
Hadoop MapReduce is a powerful framework for processing vast amounts of data across a distributed cluster. It follows a simple yet effective programming model, allowing developers to write applications that process petabytes of data in parallel on large clusters. In this post, we'll explore the key components of Hadoop MapReduce and how it works and provide some examples to help you get started.
Key Components of Hadoop MapReduce
- JobTracker: Manages the job execution across the cluster. It schedules tasks, monitors them, and re-executes the failed tasks.
- TaskTracker: Executes the tasks as directed by the JobTracker.
- Input Split: The logical representation of data processed by a single Mapper.
- Data Node: Stores the Hadoop Distributed File System (HDFS) data.
Here is a high-level diagram showing the architecture of Hadoop MapReduce:
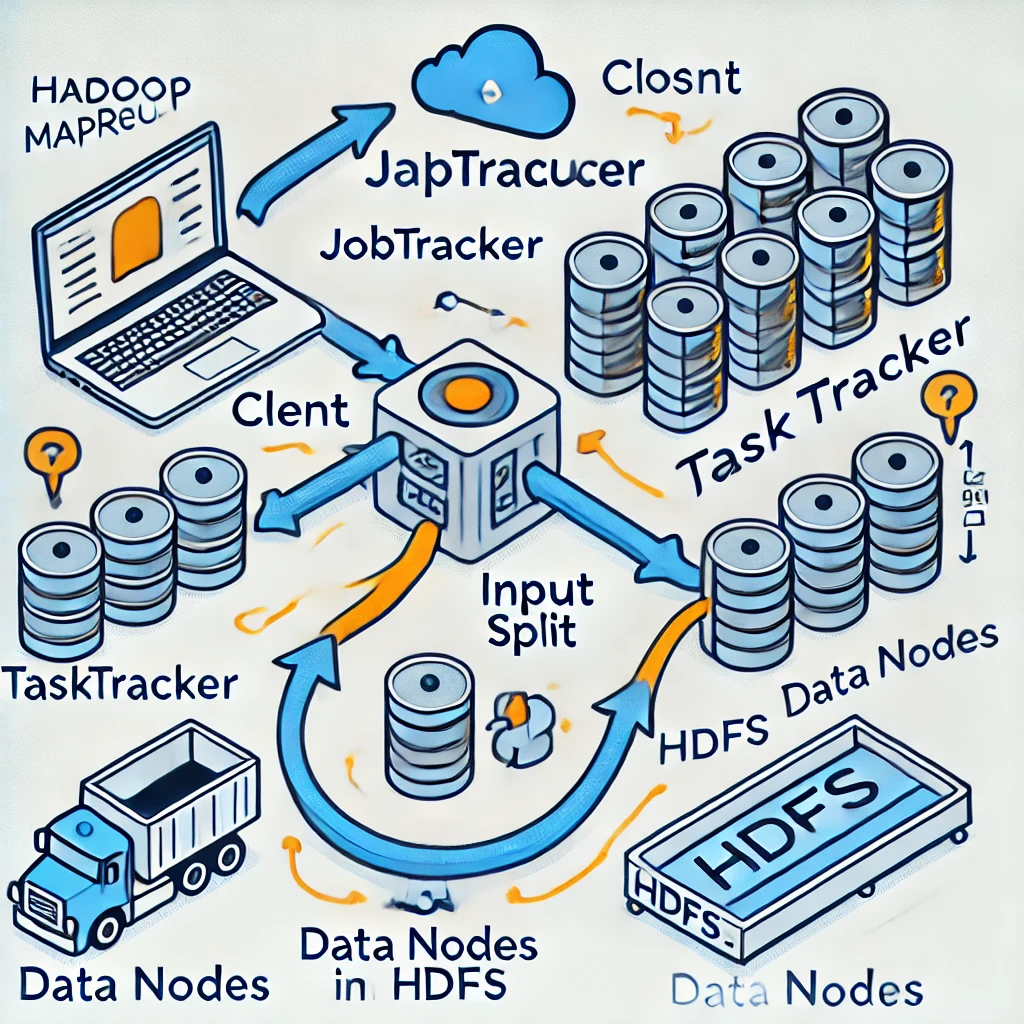
How Hadoop MapReduce Works
1. Input Phase:
- Data is split into chunks (Input Splits).
- Each chunk is processed by a separate Mapper.

2. Map Phase:
- The Mapper processes each input split and generates intermediate key-value pairs.

3. Shuffle and Sort Phase:
- Intermediate key-value pairs are shuffled and sorted by keys.

4. Reduce Phase:
- The Reducer processes the sorted key-value pairs and generates the final output.

Example: Word Count Program
Let's consider a simple example of a word count program. This program counts the occurrences of each word in a set of input documents.
Map Function
The Map function reads the input text line by line, splits each line into words, and emits a key-value pair for each word.
def map_function(key, value): for word in value.split(): emit(word, 1)
Reduce Function
The Reduce function receives each word and a list of counts, sums them up, and emits the total count for each word.
def reduce_function(key, values): total_count = sum(values) emit(key, total_count)
Conclusion
Hadoop MapReduce is a fundamental framework for processing large-scale data in a distributed environment. By understanding its components and workflow, you can leverage its power to build efficient and scalable data processing applications.
I hope this blog post helps you understand Hadoop MapReduce. Feel free to leave your comments or questions below!
